


















Easier Data Marts with DreamFactory Data Mesh
by Jason Gilmore • January 22, 2024
Today's IT teams are struggling to make sense of organizational data that has been compiled piecemeal and often stored within disparate storage solutions. Often this information needs to be aggregated and presented in a unified format, yet pulling data from multiple data sources and displaying it in a coherent way can be onerous and error-prone. The challenge is compounded when the data resides in different databases, and possibly within different clouds.
To remedy this, companies often embark upon costly and time consuming data lake, data mart, and data warehouse projects. In many cases though, the IT team is simply looking for an effective solution to combine data within a single unified interface!
In this tutorial I'll introduce you to a powerful and very popular feature of the DreamFactory platform called Data Mesh. Using Data Mesh you can create virtual relationships between two databases much in the same way you can create foreign key relationships between two database tables. We'll walk through an example in which a MySQL database running on Amazon RDS is meshed with an IBM DB2 database running on IBM Cloud, merging the data together so it can be retrieved via a single API endpoint.
Here's the key things to know about DreamFactory's data marts:
- Data Mesh is a decentralized approach to data architecture that emphasizes domain-specific ownership and autonomous management of data as a product.
- It offers several benefits including improved data quality, enhanced data democratization, scalability, and reduced bottlenecks in data management.
- Key principles of Data Mesh include domain-oriented ownership, self-serve data infrastructure, federated computational governance, and product thinking.
- Data Marts, subsets of data warehouses, are tailored to specific business functions, offering improved performance, business-focused insights, enhanced data governance, and agile analytics.
- DreamFactory's Data Mesh enhances ERP functionality by enabling custom reports and integrations, ensuring secure data access, and providing flexible, API-based data querying and migration.

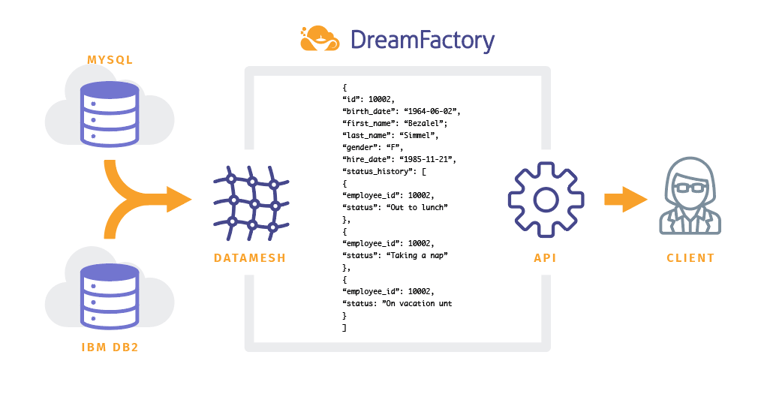
What is Data Mesh?
Data Mesh, introduced by Zhamak Dehghani, is a decentralized approach to data architecture that advocates for a self-serve, domain-oriented model. It aims to address the challenges associated with centralized data platforms and traditional monolithic data architectures. By distributing data ownership and management to individual domain teams, Data Mesh embraces the principles of autonomy, alignment, and product thinking.
Key Principles of Data Mesh
- Domain-Oriented Ownership: In a Data Mesh, data is treated as a product, and each domain team becomes responsible for their own data products. This approach promotes accountability, as the teams have a better understanding of the data's context, quality, and usage within their domain.
- Self-Serve Data Infrastructure: Data Mesh empowers domain teams by providing them with self-serve data infrastructure. This infrastructure includes data pipelines, storage, processing, and governance tools that enable teams to manage and deliver their data products independently.
- Federated Computational Governance: Unlike a centralized data team, Data Mesh embraces the concept of federated computational governance. This means that governance responsibilities are distributed among domain teams, who understand the specific context and requirements of their data. It fosters a culture of collective ownership and accountability.
- Product Thinking and Data Products: Data Mesh encourages teams to think of data as a product and treat it accordingly. This involves defining clear data product boundaries, establishing product-specific APIs, and ensuring data quality through automated testing and monitoring. By adopting a product mindset, teams can focus on delivering value and fostering innovation.
Benefits of Data Mesh
Data Mesh offers improved data quality and reliability by empowering domain teams to take ownership of their data products. This decentralized approach enhances accountability and reduces the burden on centralized data teams.
Data Mesh can promote enhanced data democratization, enabling domain teams to access and analyze data independently. This empowers teams to make faster and more informed decisions, fostering a data-driven culture across the organization. Data Mesh architecture can also ensure scalability and flexibility, accommodating the diverse needs of different domains.
Data Mesh also reduces bottlenecks and dependencies by distributing responsibilities and fostering autonomy among domain teams. This improves agility and minimizes reliance on a single point of failure, leading to more efficient data processes.
What are Data Marts?
Data marts are subsets of data warehouses that are designed to serve the analytical needs of specific departments, teams, or business functions within an organization. They are tailored to provide relevant and easily accessible data for decision-making and analysis within a specific domain.
Benefits of Data Marts
The primary purpose of data marts is to provide optimized and streamlined access to data for specific user groups. Some key benefits of data marts include:
- Improved Performance: Data marts are designed to cater to the specific analytical requirements of a particular business function. By focusing on a specific subset of data, they can deliver faster query response times and improved performance compared to querying the entire data warehouse.
- Business-Focused Insights: Data marts are structured to align with the needs of specific departments or teams. By providing tailored data sets, they enable users to gain insights that are directly relevant to their business functions, leading to more informed decision-making and improved operational efficiency.
- Enhanced Data Governance: Data marts allow for greater control and governance over data access and usage. Since they focus on specific domains, data stewards can ensure data quality, integrity, and compliance within the context of those domains, facilitating better data governance practices.
- Agile and Scalable Analytics: Data marts enable agility and scalability in analytics efforts. They can be built incrementally, adding new data sources or refining existing ones to meet evolving business needs. This flexibility allows organizations to adapt their analytics capabilities as requirements change over time.
Want to Watch a Video on this Topic Instead?
A video-based version of this tutorial is available at https://academy.dreamfactory.com. Or just click on the video below!
Configuring the MySQL and IBM DB2 APIs
For the purposes of this tutorial I'll assume you're already familiar with DreamFactory fundamentals, including how to generate database-backed REST APIs. If you'd like to follow along in your own environment, you'll need to configure two database APIs within your DreamFactory instance.
Configuring Data Mesh
After generating your APIs, enter DreamFactory's Schema component and select the API and table that will serve as the relationship parent. In the following screenshot I've chosen the MySQL API and the employees table:
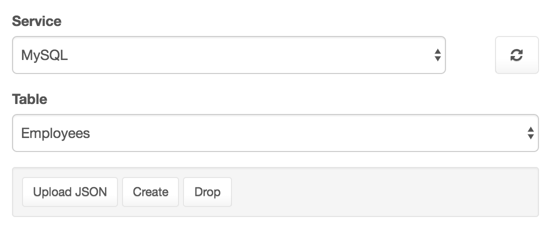
Once selected, you can scroll down to the table's "Relationships" section. This section warrants a bit of explanation. When DreamFactory generates a database API, it analyzes all tables, stored procedures, views, table columns and datatypes, and foreign key relationships. This section contains a list of join aliases that you can use to easily join tables via the API:
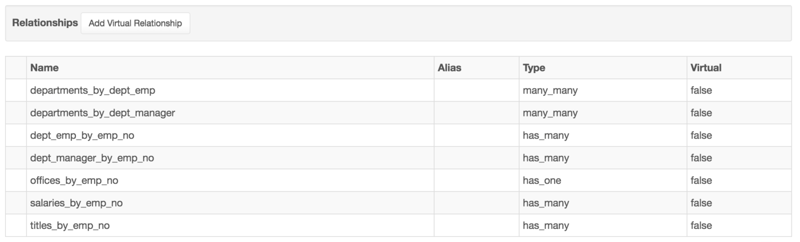
However you're not limited to these aliases; by clicking the Add Virtual Relationship button you can create new relationships where they didn't previously exist, including relationships between two databases. Click on the Add Virtual Relationship button and you'll be presented with an interface for defining the relationship between two databases. See the following screenshot:

In this screenshot, I've defined the fields as follows:
Always Fetch: This field enables the virtual relationship. You can also optionally enable the relationship on demand via the API.
Type: This field determines the relationship type. You can choose fromBelongs To,Has One,Has Many, andMany to Many.
Reference Service: This field identifies the related service. It's set toDB2because the relationship pertains to the previously configured IBM DB2 API.
Reference Table: This field identifies the related table. Recall we selected theMySQLservice'semployeestable, so we're going to relate theemployeestable to theDB2service'semployee_statustable.
Reference Field: This field identifies the foreign key field found in the relatedemployee_statustable.
After defining these fields, save the changes and you're ready to begin using the new relationship!
Querying the Relationship
Now that the relationship has been defined, let's execute a query and view the combined results. We'll begin by showing what a query to the employees table looks like prior to configuring Data Mesh:

After querying Data Mesh, the results look like this:
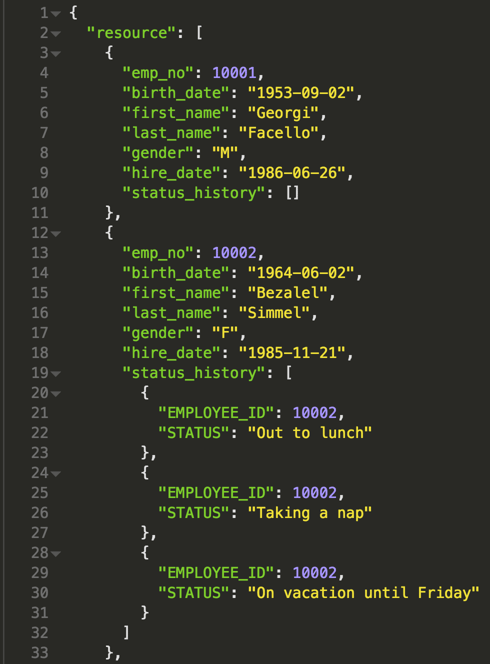

Conclusion
DreamFactory's Data Mesh feature offers an incredibly straightforward, point-and-click solution for creating sophisticated and transparent unified queries. You're certainly not limited to meshing two databases together; try meshing two, three, or more databases together and marvel over the time and aggravation savings!
FAQs on DreamFactory's Data Mesh for Unified Data Management
What is Data Mesh?
Data Mesh is a decentralized data architecture approach that treats data as a product, emphasizing domain-specific ownership and management. This method helps overcome challenges associated with traditional centralized data platforms, promoting autonomy, alignment, and product thinking.
How Does Data Mesh Benefit IT Teams?
Data Mesh offers:
- Improved Data Quality: By empowering domain teams to own their data products.
- Enhanced Data Democratization: Allows teams to access and analyze data independently.
- Scalability and Flexibility: Accommodates diverse domain needs.
- Reduced Bottlenecks: Distributes responsibilities, enhancing efficiency.
What are the Key Principles of Data Mesh?
The core principles include:
- Domain-Oriented Ownership: Teams are responsible for their data products.
- Self-Serve Data Infrastructure: Equips teams with tools for managing data products.
- Federated Computational Governance: Distributes governance responsibilities.
- Product Thinking: Encourages viewing data as a product.
What are Data Marts?
Data Marts are subsets of data warehouses, tailored to specific departments or business functions. They provide relevant and accessible data for domain-specific decision-making.
Benefits of Data Marts?
Key advantages include:
- Improved Performance: Optimized for specific analytical requirements.
- Business-Focused Insights: Delivers data relevant to specific departments.
- Enhanced Data Governance: Better control over data quality and compliance.
- Agile Analytics: Flexible to adapt to changing business needs.
How Does DreamFactory's Data Mesh Enhance ERP Functionality?
DreamFactory’s Data Mesh allows for:
- Custom Reports and Integrations: Without altering ERP functionality.
- Security: Ensures secure data access across various sources.
- Flexibility: Provides an API-based interface for agile data querying and migration.
Related Reading:
TL;DR - GET AN AI SUMMARY
Jason is the author of almost a dozen books on web development, including most recently Easy Laravel 5, and Beginning PHP and MySQL, 4th Edition. He's the co-founder of the CodeMash Conference, one of the largest software conferences in the Midwestern United States. Jason serves as a technical advisor to the boards of several technology startups. His free time is spent playing with his kids and reading.
