
Picture this: a customer reaches out with a seemingly simple request—convert a date field to a different format in their API responses. The catch? They only have read-only access to their database, which means no schema updates, no new columns, just pure data transformation. This intriguing challenge led us down the rabbit hole to rediscover one of DreamFactory's most powerful yet underutilized features: enhancing API calls with SQL functions.
Through this journey, we realized the immense potential of manipulating data, creating virtual fields, and performing complex calculations—all without altering the underlying database schema. In this post, we’ll explore how you can leverage these capabilities to streamline data processing and deliver more insightful and useful API responses.
As the Technical Support Lead at DreamFactory, I've had my fair share of diving into the depths of our platform. This is my first blog post for the company, and I couldn't be more excited to share these rediscovered gems with you. Let's dive in!

Setting Up the Database
Before diving into the features, let's set up a sample database table to work with. We'll create a table called `DB_FUNC_DEMO` with various fields, insert sample data, and then demonstrate how DreamFactory enhances API calls using SQL functions.
Let’s just pretend this is a table of LLM training data, representing a total amount of samples and a measurement from those samples. I’m using a table schema like this so that as we play with these database functions, we can try some interesting applications for some of the most commonly used SQL data types.
All of the following is done with a SQL client pointed to a MySQL database. This functionality will work with any of our SQL databases (such as SQL Server, Postgres and even Snowflake), however the exact syntax for the database functions will differ slightly. (ex: SQL Server wants field names in curly braces {} ).
The following script will build and populate the table I’ll be working with. If you’d like to follow along, simply create the same table in your database and set up a database API to that database in the DreamFactory UI.
SQL Script
CREATE TABLE DB_FUNC_DEMO (
ID INT PRIMARY KEY AUTO_INCREMENT,
description VARCHAR(255),
is_active BOOLEAN,
record_date DATE,
measurement FLOAT,
sample_count INT,
error_count INT
);
INSERT INTO DB_FUNC_DEMO (description, is_active, record_date, measurement, sample_count, error_count) VALUE
S
('Initial data collection', TRUE, '2023-01-01', 120.45678, 100, 5),
('Secondary data validation', FALSE, '2023-01-02', 98.76543, 200, 10),
('Preliminary analysis', TRUE, '2023-01-03', 76.54321, 150, 3),
('Data cleaning phase', TRUE, '2023-01-04', 89.32123, 250, 7),
('Final analysis', FALSE, '2023-01-05', 105.78901, 300, 12),
('Model training', TRUE, '2023-01-06', 110.22456, 400, 4),
('Model validation', FALSE, '2023-01-07', 94.33444, 350, 6),
('Hyperparameter tuning', TRUE, '2023-01-08', 87.91234, 220, 9),
('Model deployment', TRUE, '2023-01-09', 102.65432, 270, 11),
('Post-deployment monitoring', FALSE, '2023-01-10', 95.47654, 320, 8);
Retrieving Data
Once the table is connected to DreamFactory under a {service_name}, you can see the data as we progress with a GET request in the API docs to: {DreamFactory IP/DNS}/api/v2/{service_name}/_table/db_func_demo/
At the start you should see a payload like:
{
"resource": [
{
"ID": 21,
"description": "Initial data collection",
"is_active": true,
"record_date": "2023-01-01",
"measurement": 120.457,
"sample_count": 100,
"error_count": 5
},
{
"ID": 22,
"description": "Secondary data validation",
"is_active": false,
"record_date": "2023-01-02",
"measurement": 98.7654,
"sample_count": 200,
"error_count": 10
},
{
"ID": 23,
"description": "Preliminary analysis",
"is_active": true,
"record_date": "2023-01-03",
"measurement": 76.5432,
"sample_count": 150,
"error_count": 3
},
{
"ID": 24,
"description": "Data cleaning phase",
"is_active": true,
"record_date": "2023-01-04",
"measurement": 89.3212,
"sample_count": 250,
"error_count": 7
},
{
"ID": 25,
"description": "Final analysis",
"is_active": false,
"record_date": "2023-01-05",
"measurement": 105.789,
"sample_count": 300,
"error_count": 12
},
{
"ID": 26,
"description": "Model training",
"is_active": true,
"record_date": "2023-01-06",
"measurement": 110.225,
"sample_count": 400,
"error_count": 4
},
{
"ID": 27,
"description": "Model validation",
"is_active": false,
"record_date": "2023-01-07",
"measurement": 94.3344,
"sample_count": 350,
"error_count": 6
},
{
"ID": 28,
"description": "Hyperparameter tuning",
"is_active": true,
"record_date": "2023-01-08",
"measurement": 87.9123,
"sample_count": 220,
"error_count": 9
},
{
"ID": 29,
"description": "Model deployment",
"is_active": true,
"record_date": "2023-01-09",
"measurement": 102.654,
"sample_count": 270,
"error_count": 11
},
{
"ID": 30,
"description": "Post-deployment monitoring",
"is_active": false,
"record_date": "2023-01-10",
"measurement": 95.4765,
"sample_count": 320,
"error_count": 8
}
]
}
(You could also of course use an external HTTP client such as Postman,)
Leveraging SQL Functions with DreamFactory
Now that there is a dataset to play with, let’s dive into how these database functions work, and what they might be used for.
DreamFactory can enhance the data retrieved through its APIs by applying SQL functions directly within the API call. This is incredibly useful for data manipulation, data (re)formatting, and creating virtual fields based on SQL logix on the fly. Here's a look at some examples:
String Manipulation
Starting with the simplest easiest way to do show a database function at work, let’s look at string manipulation. I’ll use this example to walk through how to add a database function, and later examples will simply highlight what would change from this process.
To being adding database functions to a field, navigate to Admin Settings and then Schema. Select the name of the service connection you set up earlier, and then the db_func_demo table. You should see something ike:
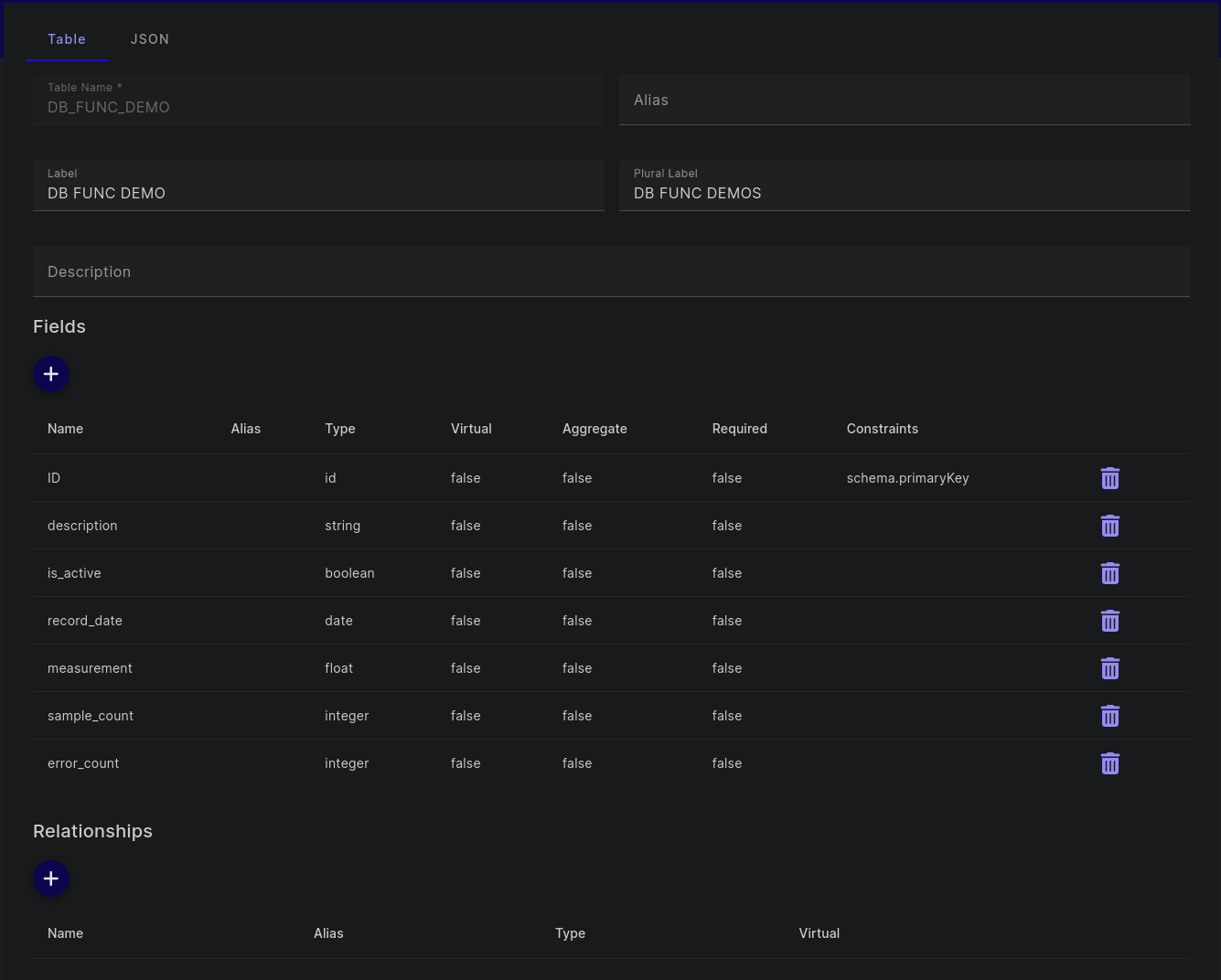
From here, select the “description” field to start, our only string field (for now…). You’ll be met with the field specific schema description portion of the UI. Look to the bottom of the screen for the “DB Function Use” section, expand it, and for “use” select just SELECT (GET) and for function add: UPPER(description) will look something like:

For SQL Server, your function will look something like: UPPER({description}) some other database types want double quotes around the column name. There will be an “under the hood” section of this post at the end that explains how to figure out the right syntax in an easier way.
once entered, scroll down and click save, then head back to the API docs or your HTTP client of choice. Make the same call again and look at your result:
{
"resource": [
{
"ID": 21,
"description": "INITIAL DATA COLLECTION",
"is_active": true,
"record_date": "2023-01-01",
"measurement": 120.457,
"sample_count": 100,
"error_count": 5
},
Congrats, you just bullseye’d a Womp Rat with your T-16.
Date Functions
As mentioned in the beginning of this post, the original dive into this subject was from a need to make some adjustments to a date field. We are going to do something more ridiculous than what this customer did…because it’s fun, and because we can. I want to know the day of the week each one of these “records” was made on.
That being said, head back into the schema page for the demo table, but this time click on the “record_date” field. Add to your DB function like so:

That function for copy/paste is:
DATE_FORMAT(record_date, "%W %M %e %Y")
Make that same API call again and check out the results:
{
"resource": [
{
"ID": 21,
"description": "INITIAL DATA COLLECTION",
"is_active": true,
"record_date": "Sunday January 1 2023",
"measurement": 120.457,
"sample_count": 100,
"error_count": 5
},
The exact function might differ here based on your database engine, especially when it comes to datetime codes. For MySQL you can find those Here.
While your use case might not want the day of the week, you can see how flexible this could make the presentation of datetime data.
Playing WIth Floats
No “hello world” type of example for a tech blog would be complete without showing rounding floats to 2 digits. Simple, same as before, but this time choose the “measurement” field, and for your DB function. add: ROUND(measurement, 2)
and run your call again.
{
"resource": [
{
"ID": 21,
"description": "INITIAL DATA COLLECTION",
"is_active": true,
"record_date": "Sunday January 1 2023",
"measurement": 120.46,
"sample_count": 100,
"error_count": 5
},
Conditional Logic
So far, we have just looked at what can be done with formatting/representing the data differently. But what if one wanted to change the value of an existing field, based on logic on the values of other fields? We can do that too.
This time, grab the “is_active” field. We’re going to say that if we have less than 150 samples, the training session is not active. In the DB function field add: IF(sample_count > 150, 1, 0)
Save, head back to your HTTP client, check out your results.
As a bonus, if you add ?fields=sample_count,is_active to the url of the request, you can limit the response to those two fields to make sure the logic is working:
{
"resource": [
{
"is_active": false,
"sample_count": 100
},
{
"is_active": true,
"sample_count": 200
},
{
"is_active": false,
"sample_count": 150
},
{
"is_active": true,
"sample_count": 250
},
Obviously, this is a pretty simple example, but you can imagine how much more complex we could be. In this next example, we’ll go a little over the top.
Virtual Fields and You!
In DreamFactory we can also create virtual fields in the Schema section of the UI. This enables us to add more information to each record without editing anything in the original SQL table. There are many reasons why an additional logic-based field might be needed, but let’s say we want something more granular that a simple boolean for active status.
Go into the schema section of the UI for the table (the screen where you select the individual fields) and click the blue plus to add a new one. I’m going to call this field “status”, and the Type as a string. Then, check the “Is Virtual” field option, as well as “Allows Null”.
Go ahead and add the following IF statement to the DB Function field:
IF(sample_count > 300, 'Very Active', IF(sample_count BETWEEN 200 AND 300 AND error_count < 5,
'Active with Few Errors', IF(sample_count BETWEEN 200 AND 300 AND error_count >= 5,
'Active with Many Errors', IF(sample_count BETWEEN 100 AND 200, 'Moderately Active',
IF(sample_count < 100 AND is_active = TRUE, 'Low Activity but Active', 'Inactive')))))
Alright, go make that GET request again, and check your results.
{
"resource": [
{
"ID": 21,
"description": "INITIAL DATA COLLECTION",
"is_active": false,
"record_date": "Sunday January 1 2023",
"measurement": 120.46,
"sample_count": 100,
"error_count": 5,
"status": "Moderately Active"
},
{
"ID": 22,
"description": "SECONDARY DATA VALIDATION",
"is_active": true,
"record_date": "Monday January 2 2023",
"measurement": 98.77,
"sample_count": 200,
"error_count": 10,
"status": "Active with Many Errors"
},
{
"ID": 23,
"description": "PRELIMINARY ANALYSIS",
"is_active": false,
"record_date": "Tuesday January 3 2023",
"measurement": 76.54,
"sample_count": 150,
"error_count": 3,
"status": "Moderately Active"
},
Pretty neat huh? One of the coolest things about this (in my opinion), this logic is happening at the fastest place it can, right on your database. If you thought that was fun, stay with me, these next two examples are pretty neat.
Aggregation and Math
In addition to virtual fields, we can also create aggregate virtual fields. This could enable analytics to run on large datasets, and customized queries to be formed, go back to the table view in the schema section, and create another new field.
I am naming this one avg_samples, setting it to an integer type, check virtual, and Is Aggregate. Make sure its’ use is SELECT, and the DB function should be: AVG(sample_count)
When you make the request this time, add ?fields=avg_samples to your request, or type “avg_samples” into the “fields” section of the API Docs UI. Make your request, my result was 256.
Want to go even deeper? Add a filter to the request: ?filter=error_count > 10 (error_count > 10 if using API Docs) and run it again. A client side application could easily dynamically change that filter to adjust whatever records you are trying to get an average of in the future. MIN, MAX, COUNT, all the other fun SQL Math functions also work here when working with integer/float fields.
The Func the Whole Func and Nothing but the Func
Just to really drive the point home, the last example before I discuss some of the logic behind the Database Functions feature is using a user defined stored function to define a value of a virtual field. In your SQL workbench of choice, create a stored function like:
DELIMITER //
CREATE FUNCTION GetSampleSummaryFunction(p_sample_count INT, p_error_count INT)
RETURNS VARCHAR(255)
DETERMINISTIC
BEGIN
DECLARE p_good_samples INT;
DECLARE p_summary VARCHAR(255);
SET p_good_samples = p_sample_count - p_error_count;
SET p_summary = CONCAT(
'The total samples are: ', p_sample_count,
', with ', p_error_count, ' errors that makes ',
p_good_samples, ' successful samples'
);
RETURN p_summary;
END //
DELIMITER ;
It’s important to note here, that the user DreamFactory is using to connect to the database also needs permissions to run this function. Easiest way to make sure this is the case is by creating the function with the user DreamFactory is using.
Now, back in the schema section for the table, make another field. I am calling it “sample_summary” it is a string field, virtual, and we will also allow Null. Define the DB function like: "GetSampleSummaryFunction(sample_count, error_count)”
Save, and run your request again. (make sure to remove fields= or filters as appropriate).
This is without a doubt my favorite one, look at that payload:
{
"resource": [
{
"ID": 21,
"description": "INITIAL DATA COLLECTION",
"is_active": false,
"record_date": "Sunday January 1 2023",
"measurement": 120.46,
"sample_count": 100,
"error_count": 5,
"status": "Moderately Active",
"sample_summary": "The total samples are: 100, with 5 errors that makes 95 successful samples"
},
{
"ID": 22,
"description": "SECONDARY DATA VALIDATION",
"is_active": true,
"record_date": "Monday January 2 2023",
"measurement": 98.77,
"sample_count": 200,
"error_count": 10,
"status": "Active with Many Errors",
"sample_summary": "The total samples are: 200, with 10 errors that makes 190 successful samples"
},
Finally, I’ll briefly show what’s happening under the hood, so you can take these examples and expand on them later.
Query Logging
If you’ve made it this far, you’re probably fairly SQL savvy and already roughly understand what’s happening, it’s not all that complex. DreamFactory is taking your DB function input and sticking it into your SELECT queries as they happen.
To follow along, and see this for yourself, you can of course use your database logs. Alternatively, you can set DB_QUERY_LOG_ENABLED=true, APP_DEBUG=true, and APP_LOG_LEVEL=debug in your .env file in the DreamFactory directory.
** BE CAUTIOUS OF DOING THIS IN PROD. THIS OPTION WILL DRAMATICALLY INCREASE THE SIZE OF YOUR LOG FILE **
With that setting changed, this is what a query might look like without any DB functions defined on the table. You can see this in the dreamfactory.log file, located in the UI or on the server itself:
service.db_func_demo: select `ID`, `description`, `is_active`, `record_date`, `measurement`, `sample_count`, `error_count` from `employees`.`DB_FUNC_DEMO` limit 1000 offset 0
(pro tip: set up another connection to the same database, but don’t add any DB functions if you want to see this yourself)
Then, when we add the DB functions on top of the call again, we’d see:
service.db_func_demo: select `ID`, UPPER(description) AS `description`,
IF(sample_count > 150, 1, 0) AS `is_active`, DATE_FORMAT(record_date, "%W %M %e %Y") AS `record_date`,
ROUND(measurement, 2) AS `measurement`, `sample_count`, `error_count`, IF(sample_count > 300, 'Very Active',
IF(sample_count BETWEEN 200 AND 300 AND error_count < 5, 'Active with Few Errors',
IF(sample_count BETWEEN 200 AND 300 AND error_count >= 5, 'Active with Many Errors',
IF(sample_count BETWEEN 100 AND 200, 'Moderately Active', IF(sample_count < 100 AND is_active = TRUE,
'Low Activity but Active', 'Inactive'))))) AS `status`, GetSampleSummaryFunction(sample_count, error_count) AS
`sample_summary` from `employees`.`DB_FUNC_DEMO` limit 1000 offset 0
Quite the mouthful.
Using the query log like above is a great way to troubleshoot what these DB functions are sending into your database if you’re getting errors. As mentioned before, different flavors of SQL want slightly different things here, but for the most part the examples shared here today are a great place to start.
Conclusion
DreamFactory’s ability to integrate SQL functions directly into API calls offers powerful capabilities for data transformation without modifying the underlying database schema. By leveraging functions like string manipulation, conditional logic, and aggregation, developers can streamline complex data processing and enhance API responses efficiently. This feature not only optimizes API performance but also simplifies delivering tailored data outputs to applications.
Want to see what the big deal is all about? Book a call with an engineer to start generating APIs behind your firewall!